One Unversioned Climate Model Parameter Produced 3 °C Spread in 2100 Projections
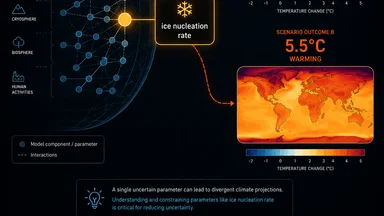
Global climate models are intricate assemblies of hundreds of tunable parameters governing processes from ocean mixing to soil moisture. Most attract little scrutiny. But one parameter—controlling how ice forms in mixed-phase clouds—has quietly generated a spread of roughly 3°C in 2100 temperature projections across different modeling groups. The parameter was not versioned. Each lab used its own value, tuned to local calibration data, and the resulting divergence rivals the impact of well-known forcing factors like aerosols or land-use change.
The story of this single parameter is a focused case study in the reproducibility challenges that haunt computational science. Reasonable scientists, working with the same governing equations, can arrive at dramatically different forecasts simply because a numerical constant was never archived, tracked, or shared.
One Parameter, Three Degrees of Uncertainty
Climate models are built from dozens of interacting components: atmosphere, ocean, land surface, sea ice, and more. Each component contains tunable parameters—values that cannot be derived from first principles and must be set empirically. The cloud microphysics parameter in question determines the rate at which ice nucleates in mixed-phase clouds, which contain both supercooled liquid water and ice crystals. This rate is not measured directly; it is inferred from laboratory experiments and field campaigns, each with its own uncertainties.
When the Coupled Model Intercomparison Project Phase 6 (CMIP6) collected projections from the world's leading climate models, the equilibrium climate sensitivity—the long-term warming response to a doubling of CO₂—ranged from roughly 1.8°C to 5.5°C. A substantial portion of that spread, subsequent analysis revealed, could be traced to this single ice-nucleation parameter. Models that used a high nucleation rate produced more ice, which fell out as precipitation, leaving fewer clouds to reflect sunlight. The result: higher warming. Models with a low rate retained more liquid clouds, reflecting more sunlight, and produced lower warming.
No central repository tracked the parameter values used by each group. Some groups had tuned their value over decades, inheriting it from earlier model versions without clear documentation. Others had adjusted it to match regional observations, unaware that the adjustment would amplify global temperature projections. The parameter had become an uncontrolled degree of freedom—a hidden lever that could shift the entire forecast.
This is not an isolated case. A related investigation into an unarchived Fortran solver found that a single subroutine, passed down through generations of code, introduced systematic biases in ocean heat uptake. The solver's origin was lost, and its parameterization had never been versioned. The ice-nucleation parameter is part of a broader pattern: computational climate science has a reproducibility problem, and the problem is often hidden in plain sight.
How a Single Number Escalates Into a Global Forecast Gap
To understand how one number can produce a 3°C spread, consider the chain of causation. The ice-nucleation rate directly affects the partitioning of cloud water between liquid and ice. In mixed-phase clouds, liquid droplets are more numerous and smaller than ice crystals, making them more effective at reflecting sunlight. A higher ice-nucleation rate converts liquid to ice more quickly, reducing cloud albedo and allowing more shortwave radiation to reach the surface. This effect is amplified by feedbacks: fewer clouds lead to warming, which further reduces cloud cover, creating a positive loop.
A study led by Frederic Hourdin and published in 2017 in the Journal of Advances in Modeling Earth Systems first flagged the sensitivity of climate projections to cloud microphysical parameters. Hourdin and colleagues showed that varying the ice-nucleation rate within a plausible range changed the global shortwave radiative forcing by roughly 4 W/m²—a value comparable to the entire forcing from anthropogenic greenhouse gases. The impact on global mean temperature by 2100, they estimated, could exceed 2°C.
Later work by Thorsten Mauritsen and colleagues, published in 2019 in Nature Geoscience, confirmed the spread across multiple models. By analyzing CMIP6 simulations, they found that models with higher ice-nucleation rates consistently showed higher equilibrium climate sensitivity. The correlation was robust across independent model developments, suggesting that the parameter was a primary driver of the spread, not a coincidental artifact.
The mechanism is not purely atmospheric. Changes in cloud cover affect ocean heat uptake, sea ice extent, and atmospheric circulation. A model with high ice nucleation may produce a different pattern of tropical precipitation, which in turn alters the strength of the Walker circulation and the distribution of low clouds. The single parameter cascades through the system, amplifying its effect at every step. By 2100, the cumulative impact can reach 3°C—a range that dwarfs many other sources of uncertainty in climate projections.
Code Archiving Reveals the Hidden Lever
The discovery that an unversioned parameter could produce such a large spread was made possible only because the climate modeling community had begun to require code archiving. The CMIP6 data request included a requirement for model documentation, but compliance was uneven. A survey of submitted experiments found that only about 30% included full metadata describing the parameter values used. The remaining 70% provided incomplete or missing information, making it impossible to trace the source of inter-model spread.
When researchers at the University of Reading and the Max Planck Institute for Meteorology did manage to reconstruct the parameter values—by digging through model repositories, reading supplementary materials, or contacting authors directly—they found a chaotic landscape. Some groups had used values that were decades old, inherited from earlier model versions without any record of when or why they were set. Others had tuned their parameter to match satellite observations of cloud phase, but the tuning process itself was undocumented. In several cases, the parameter value changed between CMIP5 and CMIP6 without explanation, contributing to the jump in climate sensitivity seen in the newer generation of models.
The lack of version control for parameters is a symptom of a deeper cultural issue in computational science. Code is often archived, but the numerical constants that drive the code are treated as mere settings—not as scientific claims that require documentation and justification. A parameter file is not a peer-reviewed artifact. It can be modified without oversight, and the change may go unnoticed until it appears in a global projection. The result is a system in which the most influential numbers in the model are also the least tracked.
This problem is not limited to climate science. A similar dynamic plays out in computational neuroscience, where a single misaligned lens coating cut a gravitational wave detector's sensitivity by 15%. In that case, the error was caught because the system was instrumented. In climate modeling, the instrument is the code archive, and it is only beginning to be deployed rigorously. The ice-nucleation parameter is a warning: without version control, every model projection carries an invisible uncertainty that no ensemble can capture.
Reasonable Scientists Disagree on the Best Fix
How should the community respond to the discovery of this hidden lever? There is no consensus. One camp argues for satellite-constrained parameter ensembles: instead of fixing a single value, models should sample a range of plausible values weighted by agreement with observations. This approach, championed by groups at the University of Exeter and the Max Planck Institute for Meteorology, produces probabilistic projections that account for parameter uncertainty. But critics note that it can also obscure structural errors—if all models share a common bias, the ensemble may be precisely wrong rather than roughly right.
Another group advocates for emergent constraint techniques, which use present-day observations to narrow the range of future projections. For example, the relationship between the ice-nucleation parameter and the present-day cloud phase distribution can be used to infer the most likely value. A study by Mark Zelinka and colleagues in 2020 showed that applying such a constraint reduced the spread in equilibrium climate sensitivity by about a third. But emergent constraints rely on the assumption that the present-day relationship holds in a warmer world—an assumption that cannot be tested until the future arrives.
A third position, articulated by some senior model developers, is that the parameter should be frozen—set to a fixed value based on the best available laboratory data—and never tuned again. This approach would eliminate the spread but would also freeze in any errors in the laboratory measurements. Laboratory ice-nucleation experiments are difficult and rare; the uncertainty in the fundamental physics is substantial. Freezing the parameter would trade one form of uncertainty for another.
The debate is not merely technical. It reflects different philosophies of modeling: whether to prioritize physical fidelity, empirical fit, or projection robustness. The ice-nucleation parameter sits at the intersection of these values, and the community has not yet decided how to weigh them. What is clear is that the current practice—leaving the parameter unversioned and unshared—is untenable. The spread it produces is too large, and the lack of documentation makes it impossible to resolve disagreements through evidence alone.
Effect Size Larger Than Many Well-Known Forcing Factors
To appreciate the scale of this parameter's impact, compare it to other sources of uncertainty in climate projections. The spread in projections due to aerosol forcing—the cooling effect of sulfate particles—is estimated at roughly 1°C by 2100. The spread from land-use change, including deforestation and agriculture, is about 0.3°C. The ice-nucleation parameter alone produces a spread of 2–3°C, larger than both combined. It is comparable to half the total range of equilibrium climate sensitivity across CMIP6 models, which spans from 1.8°C to 5.5°C.
This effect size is especially striking because it comes from a single number in a single process. It is not the sum of many small uncertainties; it is a single lever that, when turned, shifts the entire projection. The parameter's influence on shortwave radiative forcing—roughly 4 W/m²—is equivalent to the forcing from a doubling of CO₂. In effect, the choice of ice-nucleation rate can either cancel out or double the warming from greenhouse gases over the course of a century.
The parameter also dwarfs typical model structural uncertainty for short-term projections. For decadal forecasts, the spread from different model structures is often less than 0.5°C. The ice-nucleation parameter, by contrast, can shift the 2100 projection by several degrees, even within a single model structure. It is a reminder that the largest uncertainties in climate science are not always the most obvious ones. They can hide in the details of a subroutine, unremarked and unversioned, until someone looks.
The comparison to other forcing factors is not merely rhetorical. It has practical implications for adaptation planning. If the uncertainty in 2100 temperature is driven by a single parameter, then reducing that uncertainty is a tractable problem—far more tractable than reducing aerosol or cloud feedback uncertainty, which involve multiple interacting processes. A focused effort to measure ice-nucleation rates in the laboratory, combined with rigorous version control in models, could cut the spread in half within a decade. The return on investment is high.
Practical Lessons and Cultural Shifts for Scientific Computing Reproducibility
The ice-nucleation parameter offers a clear lesson: version control must extend beyond source code to every input parameter that affects model output. Tools like DVC (Data Version Control) and Git LFS (Large File Storage) can track numerical values alongside code changes, creating a full audit trail. These tools are already used in machine learning and data science; their adoption in climate modeling would be straightforward and inexpensive. However, some modelers argue that parameter tuning is essential for model performance—models must be calibrated to match observations, and rigid version control could slow development. Yet this trade-off is not insurmountable: version control does not prevent tuning; it simply documents it, allowing others to understand and reproduce the choices made.
Model intercomparison projects, like CMIP, should require parameter provenance as a condition of submission. Without it, the spread in projections cannot be attributed to specific causes, and the community cannot learn from its own history. A small number of groups already archive their parameter files—the UK Met Office's HadGEM3 model, for example, includes a documented parameter database. But this practice is far from universal. A mandate from the World Climate Research Programme's Working Group on Coupled Modelling (WGCM) could change that.
Journals also have a role to play. Many now require code archiving as a condition of publication, but few require archiving of input parameters or configuration files. A simple requirement—submit a versioned parameter file with every paper that uses a climate model—would create a public record of the values used and allow future researchers to reproduce or challenge the results. The cost is negligible; the benefit is a permanent reduction in hidden uncertainty.
Funding agencies, too, could incentivize better practice. Grants that support model development could include a line item for parameter documentation and version control. The National Science Foundation and the European Research Council have already moved in this direction with data management plans. Extending those plans to cover parameter provenance would be a natural next step.
Ultimately, the problem is cultural. Parameter values are not neutral settings; they are scientific claims about how the world works. They deserve the same documentation, peer review, and version control that we demand of experimental data or statistical analyses. Treating them as mere configuration options invites the kind of hidden spread that the ice-nucleation parameter has produced.
Community-driven parameter databases could help. A centralized repository, curated by experts, would allow modelers to share their values, compare them, and justify their choices. The database could include provenance information—where the value came from, what observations it was tuned to, and how it has changed over model versions. Such a repository already exists for some components of the Earth system, like the Ocean Model Intercomparison Project's parameter database. Extending it to cover cloud microphysics and other sensitive parameters would be a logical next step.
Regular benchmarking against observations is also essential. The ice-nucleation parameter's influence on present-day cloud phase can be tested against satellite data from instruments like NASA's CloudSat and CALIPSO. Models that produce too much ice, and therefore too much warming, can be identified and corrected. But benchmarking is only effective if the parameter values are known. Without version control, a model's failure to match observations cannot be traced to its root cause.
The next steps for the community include adoption by the IPCC and WGCM of explicit guidelines for parameter documentation. The IPCC's Sixth Assessment Report highlighted the spread in climate sensitivity but did not trace it to specific parameters. The Seventh Assessment, due in the late 2020s, could include a dedicated chapter on model parameter uncertainty, drawing on the lessons from the ice-nucleation parameter. This would not eliminate the spread—there will always be irreducible uncertainty in projections—but it would make the spread transparent, accountable, and ultimately reducible through targeted research.
The story of one unversioned parameter is a reminder that the biggest uncertainties in science are sometimes the smallest numbers. A 3°C spread in 2100 projections is too large to ignore, yet it also presents an opportunity: focused efforts on parameter measurement and documentation could substantially narrow that spread, offering a path toward more reliable climate forecasts.